Memory
메모리
CPU는 '메모리'에 올라와 있는 프로그램의 명령어들을 실행할 뿐이다. 메모리에 대해 알아보자.
목차
메모리 계층
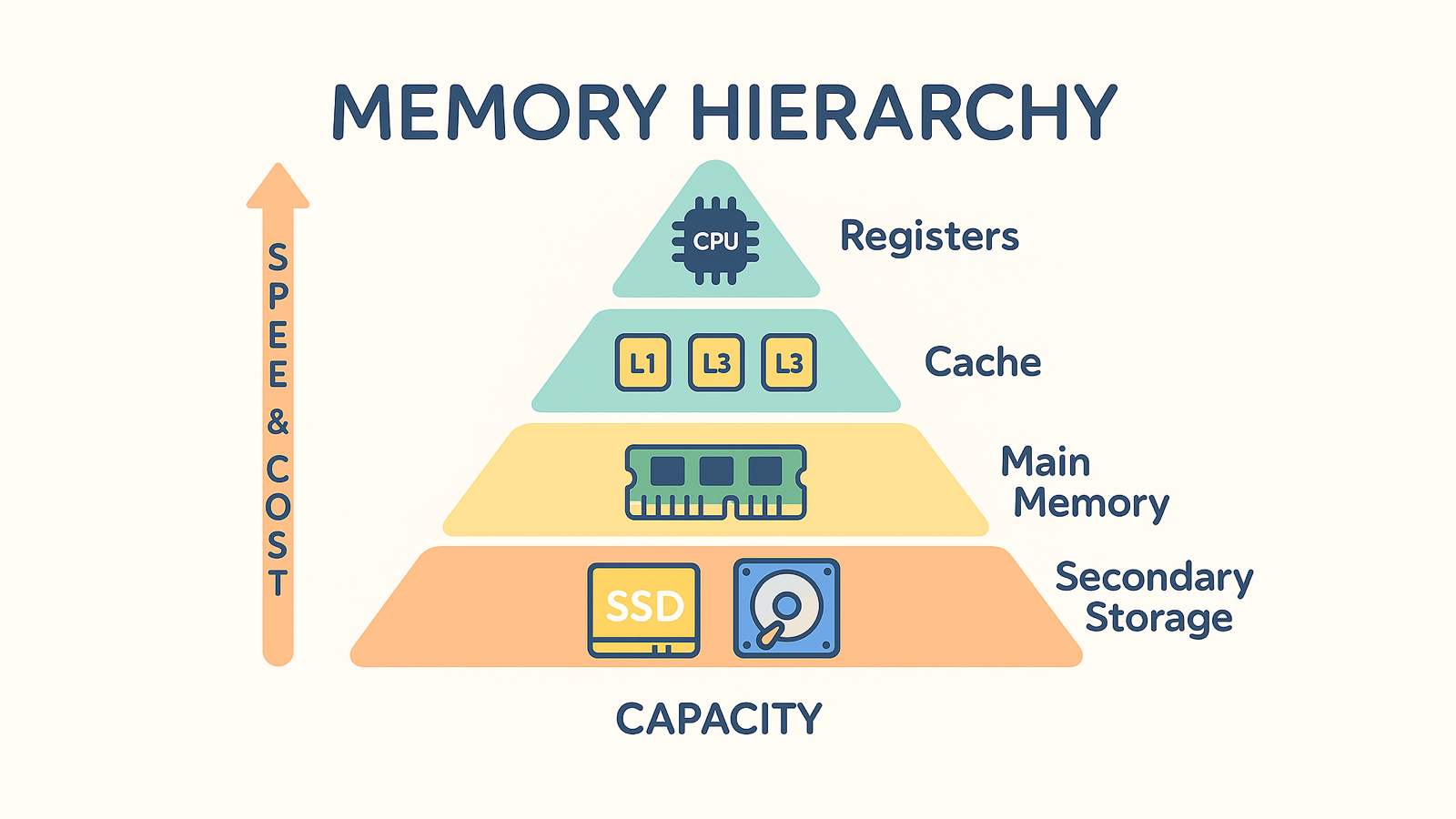
메모리 계층은 레지스터, 캐시, 주기억장치, 보조기억장치로 구성된다. CPU와 가까울 수록 용량이 작고 속도가 빠르며, CPU와 멀어질 수록 용량이 커지고 속도가 느려진다.
- 레지스터: CPU 내부에 있는 메모리로, CPU가 직접 접근할 수 있는 가장 빠른 메모리이다. 용량은 작지만 속도가 매우 빠르다.
- 캐시: L1, L2, L3 캐시를 지칭한다. CPU와 RAM 사이에 위치한 메모리로, 자주 사용되는 데이터를 저장하여 CPU의 속도를 높인다. 용량은 레지스터보다 크지만 RAM보다는 작고, 속도는 레지스터보다 빠르다.
- 주기억장치(RAM): 컴퓨터의 주 메모리로, 프로그램과 데이터를 저장한다. 용량은 캐시보다 크고 속도는 느리다.
- 보조기억장치: 하드디스크, SSD 등으로 구성된 메모리로, 대용량 데이터를 저장한다. 용량은 가장 크지만 속도는 가장 느리다.
주기억장치는 보조기억장치로부터 일정량의 데이터를 복사해서 임시로 저장하고 이를 필요 시마다 CPU에 빠르게 전달하는 역할을 한다. 이러한 메모리 계층 구조는 CPU의 성능을 극대화하기 위해 설계되었다. 각 계층은 서로 다른 속도와 용량을 가지고 있으며, CPU가 데이터를 처리하는 데 필요한 속도를 유지하면서도 대용량 데이터를 효율적으로 관리할 수 있도록 돕는다.
캐시(Cache)
캐시는 데이터를 미리 복사해 놓는 임시 저장소이자 빠른 장치와 느린 장치에서 속도 차이에 따른 병목 현상을 줄이기 위해 사용된다. 캐시는 CPU와 RAM 사이에 위치하여, CPU가 자주 사용하는 데이터를 저장하고 빠르게 접근할 수 있도록 한다. 캐시는 L1, L2, L3로 구분되며, 각 레벨은 속도와 용량이 다르다.
지역성의 원리 캐시를 직접 설계할 때, 지역성의 원리를 고려해야 한다. 지역성의 원리는 프로그램이 특정 데이터나 명령어를 반복적으로 접근하는 경향이 있다는 것을 의미한다. 지역성의 원리는 시간적 지역성과 공간적 지역성으로 나눌 수 있다.
- 시간적 지역성: 최근에 접근한 데이터나 명령어는 가까운 미래에도 다시 접근할 가능성이 높다는 원리이다. 예를 들어, 반복문에서 같은 변수에 접근하는 경우가 이에 해당한다.
- 공간적 지역성: 인접한 데이터나 명령어는 함께 접근할 가능성이 높다는 원리이다. 예를 들어, 배열의 요소를 순차적으로 접근하는 경우가 이에 해당한다.
캐시 히트(Cache Hit)와 캐시 미스(Cache Miss)
캐시에서 원하는 데이터를 찾았을 때, 이를 캐시 히트라고 한다. 반대로, 캐시에서 원하는 데이터를 찾지 못했을 때는 캐시 미스라고 한다. 캐시 미스가 발생하면, 상대적으로 느린 장치에서 데이터를 가져와야 하므로 시간이 더 소요된다.
캐시 매핑(Cache Mapping) 캐시 매핑은 메모리 주소를 캐시의 특정 위치에 매핑하는 방법이다. 캐시 매핑에는 다음과 같은 방법이 있다. 적절하지 않은 캐시 매핑은 캐시 미스를 증가시켜 성능 저하를 초래할 수 있다.
- 직접 매핑(Direct Mapping): 각 메모리 블록이 캐시의 특정 위치에 매핑되는 방식이다. 간단하지만, 충돌이 발생할 수 있다. 예를 들어, 메모리 주소의 특정 비트를 사용하여 캐시의 인덱스를 결정한다. 이 방식은 구현이 간단하지만, 동일한 캐시 위치에 여러 메모리 블록이 매핑될 수 있어 충돌이 발생할 수 있다.
- 연관 매핑(Associative Mapping): 메모리 블록이 캐시의 여러 위치에 매핑될 수 있는 방식이다. 충돌이 적지만 모든 위치를 검색해야 하므로 시간이 더 소요된다. 예를 들어, LRU(Least Recently Used) 알고리즘을 사용하여 가장 오래된 데이터를 제거하고 새로운 데이터를 추가하는 방식이다. 이 방식은 충돌이 적지만, 검색 시간이 더 소요된다.
- 세트 연관 매핑(Set Associative Mapping): 직접 매핑과 연관 매핑을 결합한 방식이다. 캐시를 여러 세트로 나누고, 각 세트는 연관 매핑을 사용한다. 예를 들어, 캐시를 4개의 세트로 나누고 각 세트는 2개의 블록을 가지는 방식이다. 이 방식은 충돌을 줄이면서도 검색 시간을 단축할 수 있다.
웹 브라우저의 캐시 웹 브라우저는 웹 페이지를 빠르게 로드하기 위해 캐시를 사용한다. 웹 페이지의 HTML, CSS, JavaScript 파일과 이미지 등을 캐시에 저장하여, 다음에 같은 페이지를 방문할 때 빠르게 로드할 수 있도록 한다. 대표적으로 쿠키, 로컬 스토리지, 세션 스토리지 등이 있다. 보통 사용자의 정보나 인증 모듈 관련 정보들을 저장하여 사용자 경험을 향상시키는 데 사용된다.
쿠키(Cookie)
쿠키는 만료 기한이 있는 키-값 저장소이다. same site 옵션을 strict로 설정하지
않았을 경우 다른 도메인에서 요청했을 때 자동 전송되며, 4KB 이하의 데이터를
저장할 수 있다.
로컬 스토리지(Local Storage) 로컬 스토리지는 만료 기한이 없는 키-값 저장소이다. 로컬 스토리지는 도메인별로 5MB의 데이터를 저장할 수 있으며, 브라우저가 종료되어도 데이터가 유지된다. HTML5를 지원하지 않는 브라우저에서는 사용할 수 없으며 클라이언트에서만 수정이 가능하다.
세션 스토리지(Session Storage) 세션 스토리지는 브라우저 세션 동안만 유지되는 키-값 저장소이다. 세션 스토리지는 탭 단위로 5MB의 데이터를 저장할 수 있으며, 탭을 닫으면 데이터가 사라진다. 세션 스토리지는 로컬 스토리지와 마찬가지로 HTML5를 지원하지 않는 브라우저에서는 사용할 수 없으며, 클라이언트에서만 수정이 가능하다.
데이터베이스의 캐싱 계층 데이터베이스 시스템을 구축할 때도 메인 데이터베이스(보조기억장치)위에 Redis와 같은 캐시 계층(주기억장치)을 두어 성능을 향상시킬 수 있다. 이러한 캐시 계층은 자주 조회되는 데이터를 메모리에 저장하여 데이터베이스의 부하를 줄이고, 응답 속도를 향상시킨다.
메모리 관리
가상 메모리(Virtual Memory)
가상 메모리는 메모리 관리 기법 중 하나로 컴퓨터가 실제로 이요 가능한 메모리 자원을 추상화하여 프로그램이 사용할 수 있는 메모리 공간을 확장하는 기술이다. 이 때, 가상으로 주어진 주소를 가상 주소라고 하며, 실제 물리적 메모리 주소는 물리 주소라고 한다. 가상 주소는 MMU(Memory Management Unit)에 의해 물리 주소로 변환되어 사용되며 사용자는 실제 주소를 의식할 필요 없이 가상 주소를 사용하여 프로그램을 작성할 수 있다. 가상 메모리는 가상 주소와 물리 주소가 매핑 되어 있고 프로세스의 주소 정보가 들어가 있는 '페이지 테이블(Page Table)'을 통해 관리된다. 이 때, 속도 향상을 위해 페이지 테이블을 캐시한 'TLB(Translation Lookaside Buffer)'를 사용한다.
스와핑(Swapping)과 페이지 폴트(Page Fault) 가상 메모리에 존재하지만 물리 메모리에 로드되지 않은 데이터나 코드에 접근하려고 할 때, 페이지 폴트가 발생한다. 이 때, 사용 가능한 빈 프레임이 없다면 스와핑을 통해 메모리에서 사용하지 않는 페이지를 디스크로 옮기고, 새로운 페이지를 메모리에 로드한다. 이를 통해 마치 페이지 폴트가 발생하지 않은 것처럼 프로그램을 실행할 수 있다.
스레싱(Thrashing)
스레싱은 페이지 폴트가 너무 자주 발생하여 시스템의 성능이 저하되는 현상이다. 스레싱이 발생하면 CPU가 페이지 폴트를 처리하는 데 많은 시간을 소모하게 되어 프로그램의 실행 속도가 크게 저하된다. 이를 방지하기 위해 메모리 크기를 확장하거나, 작업 세트를 조정하거나, PFF를 조정하는 등의 방법을 사용할 수 있다.
작업 세트(Working Set) 작업 세트는 프로세스의 과거 사용 이력인 지역성(locality)을 기반으로 결정된 페이지의 집합을 만들어서 미리 메모리에 로드하는 기법이다. 메모리에 미리 로드하여 탐색에 드는 비용을 줄이고 페이지 폴트를 최소화할 수 있다.
PFF(Page Fault Frequency) PFF는 페이지 폴트가 발생하는 빈도를 측정하여, 이를 조절하는 방법으로 상한선과 하한선을 설정하여 페이지 폴트가 너무 자주 발생하지 않도록 조절한다. 상한선에 도달하면 프레임을 추가로 할당하고, 하한선에 도달하면 프레임을 줄이는 방식으로 메모리 사용을 조절한다.
메모리 할당
메모리에 프로그램을 할당할 때는 시작 메모리 위치, 메모리 할당 크기를 기반으로 할당한다. 메모리 할당 방식에는 연속 할당과 불연속 할당이 있다.
연속 할당(Contiguous Allocation) 연속 할당은 프로그램이 메모리의 연속된 공간을 할당받는 방식이다. 이 방식은 구현이 간단하고, 메모리 접근 속도가 빠르지만, 메모리 단편화가 발생할 수 있다. 이는 고정 분할 방식과 가변 분할 방식으로 나눌 수 있다.
-
고정 분할 방식(Fixed Partitioning): 메모리를 고정된 크기의 파티션으로 나누고, 각 파티션에 프로그램을 할당하는 방식이다. 이 방식은 단순하지만, 메모리 단편화가 발생할 수 있다.
-
가변 분할 방식(Variable Partitioning): 프로그램의 크기에 따라 메모리를 동적으로 할당하는 방식이다. 이 방식은 메모리 단편화를 줄일 수 있지만, 할당과 해제 과정이 복잡해진다. 최초 적합 방식(First Fit), 최적 적합 방식(Best Fit), 최악 적합 방식(Worst Fit) 등이 있다.
- 최초 적합 방식(First Fit): 메모리에서 가장 먼저 발견되는 충분한 크기의 공간에 프로그램을 할당하는 방식이다. 구현이 간단하지만, 메모리 단편화가 발생할 수 있다.
- 최적 적합 방식(Best Fit): 메모리에서 가장 작은 충분한 크기의 공간에 프로그램을 할당하는 방식이다. 메모리 단편화를 줄일 수 있지만, 검색 시간이 길어질 수 있다.
- 최악 적합 방식(Worst Fit): 메모리에서 가장 큰 충분한 크기의 공간에 프로그램을 할당하는 방식이다. 메모리 단편화를 줄일 수 있지만, 메모리 낭비가 발생할 수 있다.
-
내부 단편화(Internal Fragmentation): 연속 할당 방식에서 발생하는 문제로, 할당된 메모리 공간이 실제로 사용되는 공간보다 크면 남는 공간이 생기게 된다. 이 남는 공간을 내부 단편화라고 한다. 예를 들어, 100KB의 메모리를 할당했지만 실제로 80KB만 사용하는 경우, 20KB의 내부 단편화가 발생한다.
-
외부 단편화(External Fragmentation): 메모리 할당과 해제를 반복하면서 발생하는 문제로, 메모리의 빈 공간이 여러 개의 작은 조각으로 나뉘어져 사용되지 않는 공간이 생기는 현상이다. 예를 들어, 100KB의 메모리를 할당하고 50KB를 해제하면, 50KB의 빈 공간이 생기지만, 다른 프로그램이 30KB를 요청하면 할당할 수 없는 상황이 발생한다.
불연속 할당(Non-Contiguous Allocation) 불연속 할당은 프로그램이 메모리의 불연속된 공간을 할당받는 방식이다. 이 방식은 메모리 단편화를 줄일 수 있지만, 구현이 복잡해진다. 메모리를 동일한 크기의 페이지(4KB)로 나누고, 프로그램마다 페이지 테이블을 두어 메모리에 프로그램을 할당하는 방식이다. 페이징 기법, 세그멘테이션 기법, 페이지드 세그멘테이션 기법 등이 있다.
- 페이징(Paging): 프로그램을 동일한 크기의 페이지로 나누고, 메모리를 동일한 크기의 프레임으로 나누어 페이지와 프레임을 매핑하는 방식이다. 이 방식은 메모리 단편화를 줄일 수 있지만, 페이지 테이블을 관리해야 하므로 구현이 복잡해진다.
- 세그멘테이션(Segmentation): 프로그램을 논리적인 단위로 나누고, 각 단위를 세그먼트라고 하여 메모리에 할당하는 방식이다. 이 방식은 프로그램의 구조를 반영할 수 있지만, 메모리 단편화가 발생할 수 있다. 공유적인 측면과 보안적인 측면에서 장점을 가지지만, 홀 크기가 균일하지 않은 단점이 있다.
- 페이지드 세그멘테이션(Paged Segmentation): 세그멘테이션과 페이징을 결합한 방식으로, 세그먼트를 페이지로 나누어 메모리에 할당하는 방식이다. 이 방식은 세그멘테이션의 장점을 살리면서도 메모리 단편화를 줄일 수 있다. 세그먼트마다 페이지 테이블을 두어 관리하며, 각 세그먼트는 페이지 단위로 메모리에 할당된다.
페이지 교체 알고리즘
메모리는 한정된 자원이므로 스와핑이 빈번하게 발생한다. 스와핑은 많이 일어나지 않도록 설계되어야 하며 이를 위해 페이지 교체 알고리즘이 사용된다. 페이지 교체 알고리즘은 페이지 폴트가 발생했을 때, 어떤 페이지를 메모리에서 제거할지를 결정하는 알고리즘이다. 페이지 교체 알고리즘에는 다음과 같은 것들이 있다.
- 오프라인 알고리즘(Offline Algorithm): 미래의 페이지 요청을 알고 있는 알고리즘으로, 가장 최적의 페이지 교체를 수행할 수 있다. 즉, 사용할 수 없는 알고리즘이지만, 이론적으로 가장 좋은 성능의 알고리즘으로 다른 알고리즘과의 성능 비교에 대한 상한 기준(upper bound)을 제공한다. 예를 들어, OPT(Optimal Page Replacement) 알고리즘이 있다. 이 알고리즘은 앞으로 가장 오랫동안 사용되지 않을 페이지를 제거한다.
- FIFO(First In First Out): 가장 먼저 들어온 페이지를 가장 먼저 제거하는 알고리즘이다. 구현이 간단하지만, 지역성을 고려하지 않아 성능이 좋지 않을 수 있다.
- LRU(Least Recently Used): 가장 오랫동안 사용되지 않은 페이지를 제거하는 알고리즘이다. 지역성을 고려하여 성능이 좋지만, '오래된' 페이지를 파악하기 위해 각 페이지마다 계수기, 스택 등을 사용해야 하므로 구현이 복잡해진다. 해시 테이블과 이중 연결 리스트의 두 개의 자료 구조를 사용하여 구현할 수 있다.
- NUR(Not Used Recently): LRU와 유사하지만, 페이지가 사용된 시간 정보를 저장하지 않고, 페이지가 사용된 횟수를 카운트하여 제거하는 알고리즘이다. 페이지가 사용되지 않은 경우, 카운트를 초기화하고, 사용된 경우 카운트를 증가시킨다. 이 알고리즘은 LRU보다 구현이 간단하다.
- LFU(Least Frequently Used): 가장 적게 사용된 페이지를 제거하는 알고리즘이다. 지역성을 고려하지만, 페이지의 사용 빈도를 추적해야 하므로 구현이 복잡해진다.