Linear Data Structures
선형 자료 구조
선형 자료 구조란 요소가 일렬로 나열되어 있는 구조를 말한다.
목차
연결 리스트
연결 리스트(Linked List)는 각 요소가 노드(Node)로 구성되어 있으며, 각 노드는 데이터와 다음 노드를 가리키는 포인터를 포함한다. 연결 리스트는 배열과 달리 요소들이 메모리 상에서 연속적으로 배치되지 않아도 되며, 동적으로 크기를 조절할 수 있어 공간적인 효율성을 극대화시킨 자료 구조이다. 삽입과 삭제가 O(1)의 시간 복잡도를 가지며, 탐색은 O(n)의 시간 복잡도를 가진다.
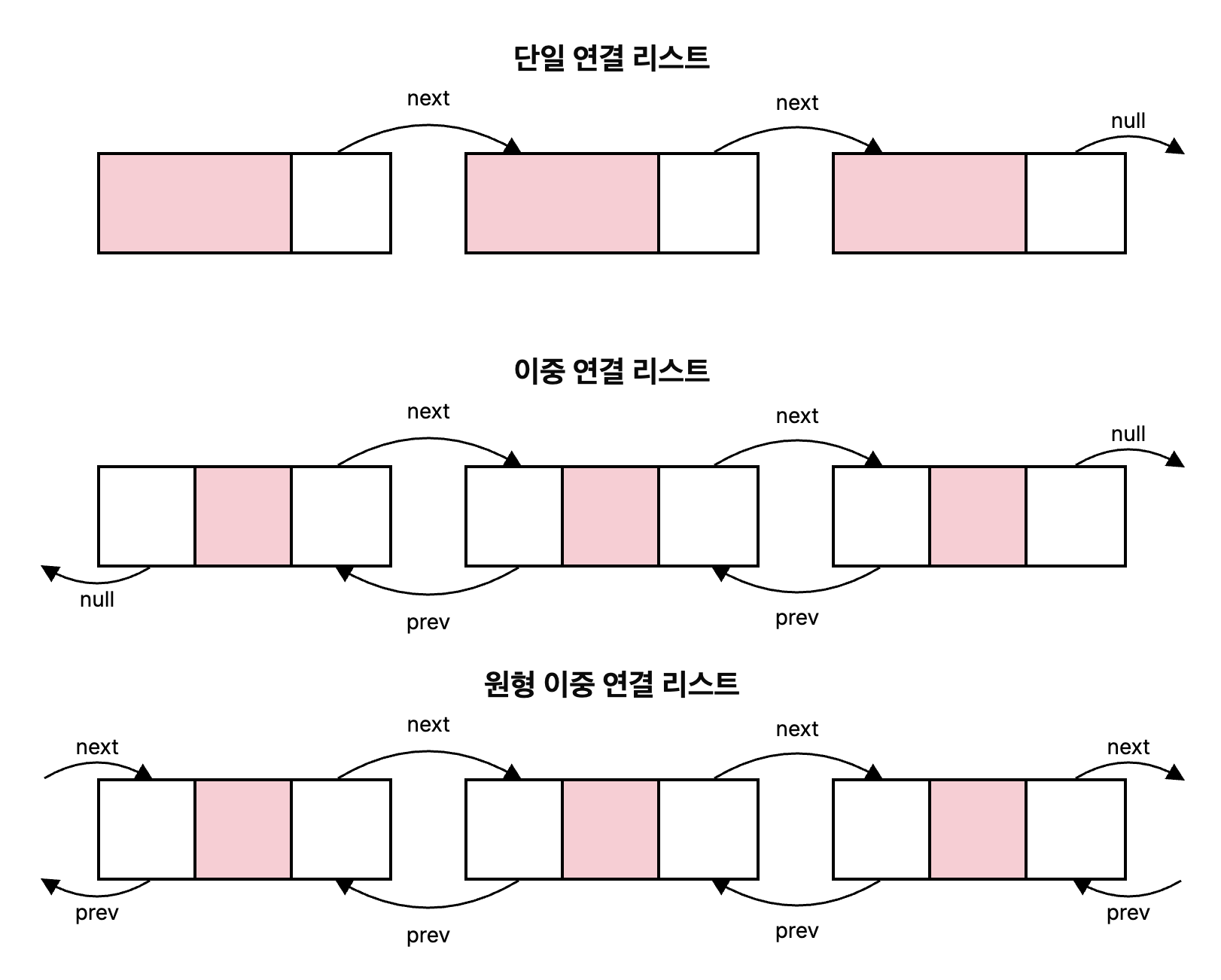
위 그림과 같이 연결 리스트는 크게 세 가지 종류로 나눌 수 있다.
- 단일 연결 리스트 (Singly Linked List): 각 노드가 다음 노드에 대한 포인터만을 가지고 있다.
- 이중 연결 리스트 (Doubly Linked List): 각 노드가 이전 노드와 다음 노드에 대한 포인터를 모두 가지고 있다.
- 원형 이중 연결 리스트 (Circular Doubly Linked List): 마지막 노드가 첫 번째 노드를 가리키며, 각 노드가 이전 노드와 다음 노드에 대한 포인터를 모두 가지고 있다.
맨 앞에 있는 노드는 헤드(Head), 맨 뒤에 있는 노드는 테일(Tail)이라고 부른다.
아래는 C++ list container의 사용 예시이다.
#include <iostream>
#include <list>
int main(int argc, char **argv) {
std::list<int> list; // -- (1)
for (int i = 0; i < 10; i++) {
list.push_back(i); // -- (2)
}
for (int i = 0; i < 10; i++) {
list.push_front(i); // -- (3)
}
list.insert(std::next(list.begin()), 100); // -- (4)
for (auto iter = list.cbegin(); iter != list.cend(); iter++) { // -- (5)
std::cout << *iter << " "; // -- (6)
}
std::cout << std::endl;
list.pop_front(); // -- (7)
list.pop_back(); // -- (8)
for (auto iter = list.cbegin(); iter != list.cend(); iter++) { // -- (9)
std::cout << *iter << " "; // -- (10)
}
std::cout << std::endl;
return 0;
}
/*
9 1000 8 7 6 5 4 3 2 1 0 0 1 2 3 4 5 6 7 8 9
1000 8 7 6 5 4 3 2 1 0 0 1 2 3 4 5 6 7 8
*/
배열
배열(Array)은 동일한 데이터 타입의 요소들이 연속적으로 메모리에 배치된 자료 구조이다. 배열은 랜덤 액세스가 가능하여, 인덱스를 통해 O(1)의 시간 복잡도로 요소에 접근할 수 있다. 그러나 배열은 고정된 크기를 가지며, 삽입과 삭제가 O(n)의 시간 복잡도를 가진다. 배열은 메모리 상에서 연속적으로 배치되기 때문에 캐시 효율성이 높아 성능이 우수하다.
랜덤 액세스와 시퀀셜 액세스
- 랜덤 액세스(Random Access): 배열과 같이 인덱스를 통해 임의의 위치에 있는 요소에 직접 접근하는 것을 의미한다. 배열은 메모리 상에서 연속적으로 배치되어 있기 때문에, 인덱스를 통해 O(1)의 시간 복잡도로 요소에 접근할 수 있다.
- 시퀀셜 액세스(Sequential Access): 연결 리스트와 같이 요소들이 순차적으로 연결되어 있어, 특정 위치에 있는 요소에 접근하기 위해서는 최대 O(n)의 시간 복잡도로 순차적으로 탐색해야 한다.
연결 리스트는 삽입, 삭제에 대해 O(1)의 시간 복잡도를 가지지만, 탐색에 대해서는 O(n)의 시간 복잡도를 가진다. 이와 반대로 배열은 탐색에 대해 O(1)의 시간 복잡도를 가지지만, 삽입, 삭제에 대해서는 O(n)의 시간 복잡도를 가진다.
아래는 C++로 구현한 배열의 예시이다.
template <typename T, size_t _Size>
class Array {
public:
T data[_Size];
...
};
int main(int argc, char **argv) {
Array<int, 10> arr; // -- (1)
for (size_t i = 0; i < 10; i++) {
arr.data[i] = i; // -- (2)
}
for (size_t i = 0; i < 10; i++) {
std::cout << arr.data[i] << " "; // -- (3)
}
std::cout << std::endl;
return 0;
}
/*
0 1 2 3 4 5 6 7 8 9
*/
벡터
벡터(Vector)는 동적 배열(Dynamic Array)로, 크기가 고정되지 않고 필요에 따라 자동으로 크기를 조절할 수 있는 자료 구조이다. 벡터는 배열과 유사하게 랜덤 액세스가 가능하여, 인덱스를 통해 O(1)의 시간 복잡도로 요소에 접근할 수 있다. 벡터는 내부적으로 배열을 사용하여 요소를 저장하며, 크기가 부족할 경우 더 큰 배열을 할당하고 기존 요소를 복사하는 방식으로 크기를 확장한다. 맨 뒤의 요소에 대한 삽입과 삭제는 O(1)의 시간 복잡도를 가지며, 이외의 요소에 대한 삽입과 삭제는 O(n)의 시간 복잡도를 가진다.
맨 뒤에 요소를 삽입하는 push_back() 메서드의 경우 O(1)의 시간 복잡도를 가지는데, 벡터의 크기를 증가시키는 로직의 시간 복잡도가 amortized 복잡도, 즉 상수 시간 복잡도 O(1)과 유사한 시간 복잡도를 가지기 때문이다.
벡터는 삽입 연산이 호출되었을 때 현재 capacity가 부족하다면 capacity의 크기를 두 배로 증가시킨다. capacity는 1, 2, 4, 8, ... 와 같이 2의 거듭제곱 형태로 증가하며, n개의 삽입 연산에 대해 총 번의 크기 증가가 발생한다.
따라서, push_back() 메서드에 대한 시간 복잡도는 아래와 같이 계산된다.
n개의 삽입 연산에 대한 총 비용이 이므로, 평균적으로 한 번의 삽입 연산에 대한 비용은 , 즉 O(1)의 시간 복잡도를 가진다.
아래는 C++ vector container의 사용 예시이다.
#include <iostream>
#include <vector>
#include <algorithm>
int main(int argc, char **argv) {
std::vector<int> vector;
for (int i = 1; i <= 10; i++) {
vector.push_back(i); // -- (1)
}
for (const int &value : vector) {
std::cout << value << " "; // -- (2)
}
std::cout << std::endl;
vector.pop_back(); // -- (3)
for (const int &value : vector) {
std::cout << value << " ";
}
std::cout << std::endl;
vector.erase(vector.begin(), std::next(vector.begin())); // -- (4)
for (const int &value : vector) {
std::cout << value << " ";
}
std::cout << std::endl;
auto iter = std::find(vector.cbegin(), vector.cend(), 100); // -- (5)
if (iter == vector.cend()) {
std::cout << "Not Found" << std::endl; // -- (6)
}
std::fill(vector.begin(), vector.end(), 10); // -- (7)
for (const int &value : vector) {
std::cout << value << " ";
}
std::cout << std::endl;
vector.clear();
for (int i = 1; i <= 10; i++) {
std::cout << vector[i] << " "; // -- (8)
}
std::cout << std::endl;
return 0;
}
/*
1 2 3 4 5 6 7 8 9 10
1 2 3 4 5 6 7 8 9
2 3 4 5 6 7 8 9
Not Found
10 10 10 10 10 10 10 10
*/
스택
스택(Stack)는 후입선출(LIFO, Last In First Out) 방식으로 동작하는 자료 구조로, 가장 나중에 삽입된 요소가 가장 먼저 제거되는 특징을 가진다. 스택은 주로 함수 호출 관리, 수식 계산, 되돌리기 기능 등에 사용된다. 스택은 삽입과 삭제가 O(1)의 시간 복잡도를 가지며, 탐색은 O(n)의 시간 복잡도를 가진다.
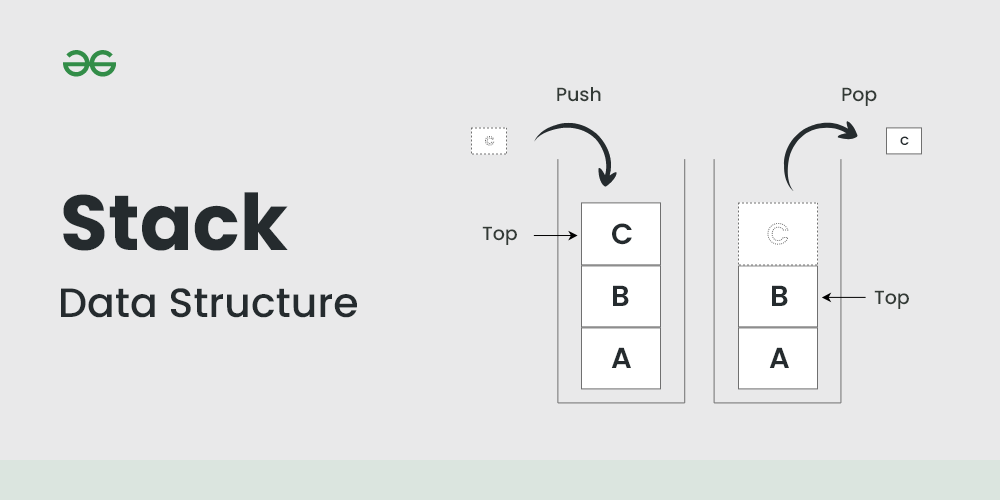
아래는 C++ stack container의 사용 예시이다.
#include <iostream>
#include <stack>
int main(int argc, char **argv) {
std::stack<int> stack;
for (int i = 1; i <= 10; i++) {
stack.push(i); // -- (1)
}
while (!stack.empty()) { // -- (2)
std::cout << stack.top() << " "; // -- (3)
stack.pop(); // -- (4)
}
std::cout << std::endl;
return 0;
}
/*
10 9 8 7 6 5 4 3 2 1
*/
큐
큐(Queue)는 선입선출(FIFO, First In First Out) 방식으로 동작하는 자료 구조로, 가장 먼저 삽입된 요소가 가장 먼저 제거되는 특징을 가진다. 큐는 주로 작업 스케줄링, 데이터 스트림 처리 등에 사용된다. 큐는 삽입과 삭제가 O(1)의 시간 복잡도를 가지며, 탐색은 O(n)의 시간 복잡도를 가진다.
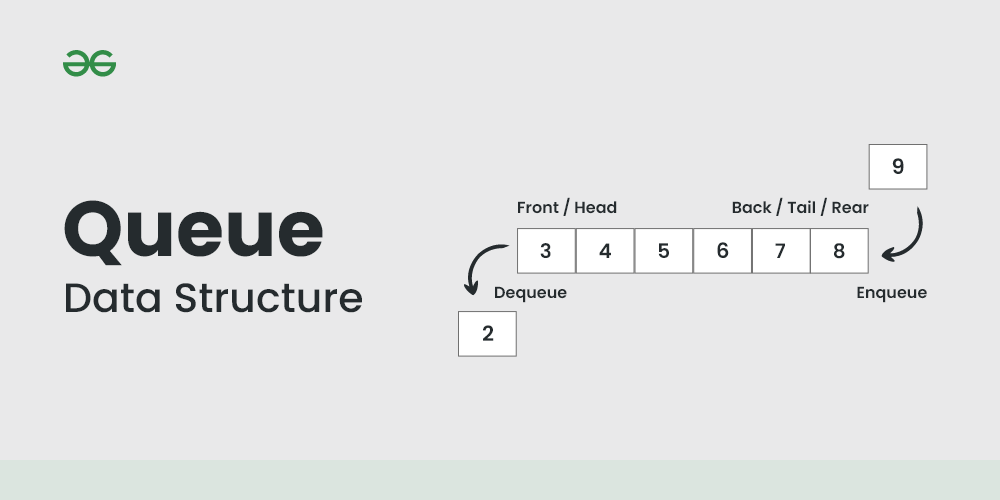
아래는 C++ queue container의 사용 예시이다.
#include <iostream>
#include <queue>
int main(int argc, char **argv) {
std::queue<int> queue;
for (int i = 1; i <= 10; i++) {
queue.push(i); // -- (1)
}
while (!queue.empty()) { // -- (2)
std::cout << queue.front() << " "; // -- (3)
queue.pop(); // -- (4)
}
std::cout << std::endl;
return 0;
}
/*
1 2 3 4 5 6 7 8 9 10
*/