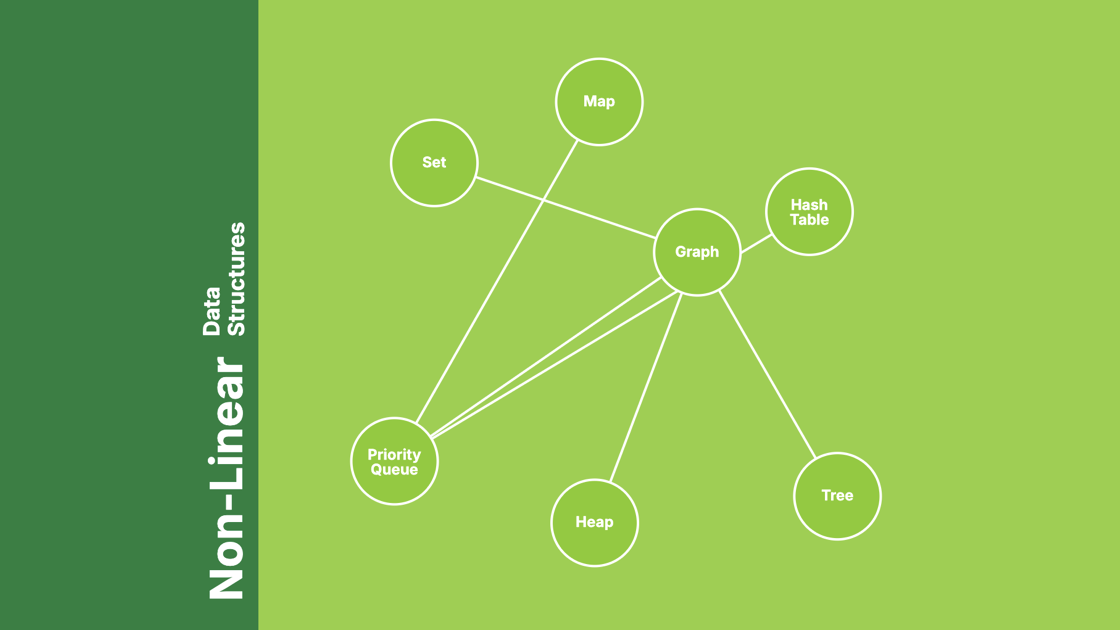
Non-linear Data Structures
비선형 자료 구조
비선형 자료 구조란 요소들이 계층적이거나 네트워크 형태로 연결되어 있는 구조를 말한다. 대표적인 비선형 자료 구조로는 트리(Tree)와 그래프(Graph)가 있다.
목차
그래프
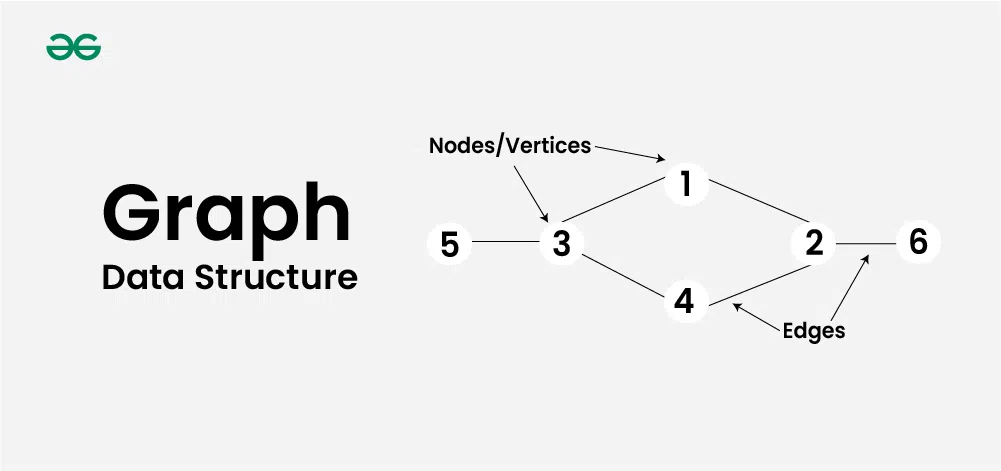
그래프(Graph)는 노드(Node)와 엣지(Edge)로 구성된 자료 구조로, 노드는 객체를 나타내고 엣지는 노드 간의 관계를 나타낸다. 그래프는 방향성 여부에 따라 방향 그래프(Directed Graph)와 무방향 그래프(Undirected Graph)로 나눌 수 있으며, 가중치 여부에 따라 가중치 그래프(Weighted Graph)와 비가중치 그래프(Unweighted Graph)로 나눌 수 있다. 그래프는 다양한 분야에서 활용되며, 특히 네트워크 분석, 경로 탐색, 소셜 네트워크, 지도 및 위치 기반 서비스 등에 사용된다.
그래프의 주요 용어는 다음과 같다.
- 노드(Node): 그래프의 기본 단위로, 객체나 데이터를 나타낸다.
- 엣지(Edge): 노드 간의 연결을 나타내며, 방향성과 가중치 여부에 따라 다양한 형태로 표현될 수 있다.
- 차수(Degree): 노드에 연결된 엣지의 수를 나타낸다. 방향 그래프에서는 진입 차수(In-degree)와 진출 차수(Out-degree)로 구분된다.
- 경로(Path): 한 노드에서 다른 노드로 이동하는 일련의 엣지들의 연속이다.
- 사이클(Cycle): 시작 노드와 종료 노드가 동일한 경로를 의미한다.
트리
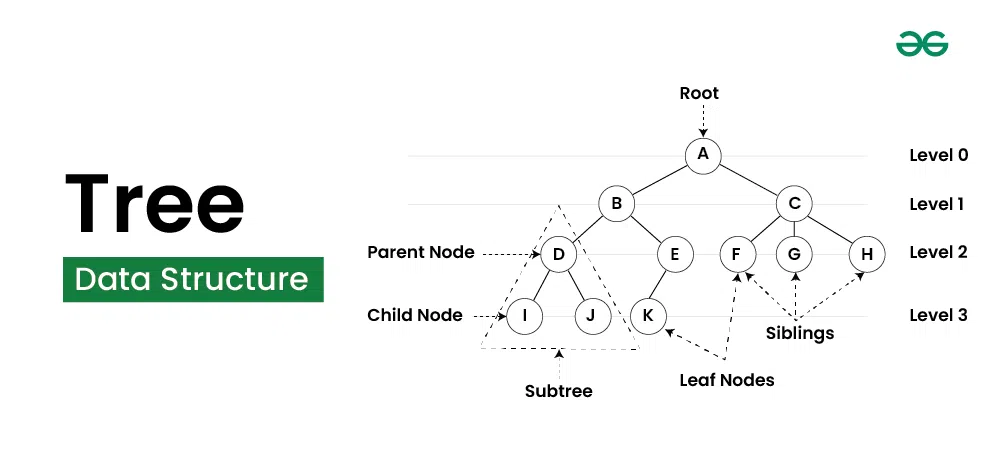
트리(Tree)는 계층적 구조를 가지는 자료 구조로, 노드들이 부모-자식 관계로 연결되어 있다. 트리는 루트 노드(Root Node)를 중심으로 시작하여, 각 노드는 자식 노드(Child Node)를 가질 수 있으며, 자식 노드는 다시 자신의 자식 노드를 가질 수 있다. 트리는 이진 트리(Binary Tree), 이진 탐색 트리(Binary Search Tree), 힙(Heap), AVL 트리(AVL Tree) 등 다양한 형태로 구현될 수 있다. 트리는 데이터의 효율적인 검색, 삽입, 삭제에 사용되며, 파일 시스템, 데이터베이스 인덱스, 표현식 트리 등 다양한 응용 분야에서 활용된다.
트리는 다음과 같은 주요 용어를 포함한다.
- 루트 노드(Root Node): 트리의 최상위 노드로, 부모 노드가 없는 노드이다.
- 자식 노드(Child Node): 특정 노드에서 직접 연결된 하위 노드이다.
- 부모 노드(Parent Node): 특정 노드에서 직접 연결된 상위 노드이다.
- 형제 노드(Sibling Node): 동일한 부모 노드를 가지는 노드들이다.
- 잎 노드(Leaf Node): 자식 노드가 없는 노드로, 트리의 가장 하위에 위치한다.
- 높이(Height): 트리의 루트 노드에서 가장 깊은 잎 노드까지의 경로 길이를 나타낸다.
- 레벨(Level): 루트 노드로부터 특정 노드까지의 경로 길이를 나타낸다.
- 서브트리(Subtree): 특정 노드를 루트로 하는 트리의 부분 집합이다.
트리는 다음과 같은 중요한 특징이 있다.
- 트리는 사이클이 없는 연결 그래프이다.
- 트리의 노드 수는 엣지 수보다 항상 하나 더 많다.
- 트리는 재귀적인 구조를 가지며, 각 서브트리 역시 트리이다.
- 임의의 두 노드 간에는 유일한 경로가 반드시 존재한다.
이진 트리
이진 트리(Binary Tree)는 각 노드가 최대 두 개의 자식 노드를 가지는 트리 구조이다. 이진 트리는 균형 이진 트리(Balanced Binary Tree)와 불균형 이진 트리(Unbalanced Binary Tree)로 나눌 수 있으며, 균형 이진 트리는 모든 잎 노드가 동일한 깊이에 위치하거나, 깊이 차이가 1 이하인 트리를 말한다. 이진 트리는 데이터의 효율적인 검색, 삽입, 삭제에 사용되며, 특히 이진 탐색 트리(Binary Search Tree)로 구현될 경우 평균적으로 O(log n)의 시간 복잡도를 가진다.
아래는 대표적인 이진 트리의 종류이다.
- 정이진 트리(Full Binary Tree): 모든 노드가 0개 또는 2개의 자식 노드를 가지는 트리이다.
- 완전 이진 트리(Complete Binary Tree): 마지막 레벨을 제외한 모든 레벨이 완전히 채워져 있으며, 마지막 레벨은 왼쪽부터 채워진 트리이다.
- 변질 이진 트리(Degenerate Binary Tree): 각 노드가 최대 하나의 자식 노드만 가지는 트리로, 일종의 선형 구조이다.
- 포화 이진 트리(Perfect Binary Tree): 모든 내부 노드가 두 개의 자식 노드를 가지며, 모든 잎 노드가 동일한 깊이에 위치하는 트리이다.
- 균형 이진 트리(Balanced Binary Tree): 모든 잎 노드가 동일한 깊이에 위치하거나, 깊이 차이가 1 이하인 트리이다.
이진 탐색 트리
이진 탐색 트리(Binary Search Tree, BST)는 이진 트리의 한 종류로, 각 노드가 다음과 같은 속성을 만족한다.
- 왼쪽 서브트리의 모든 노드의 값은 부모 노드의 값보다 작다.
- 오른쪽 서브트리의 모든 노드의 값은 부모 노드의 값보다 크다.
- 왼쪽과 오른쪽 서브트리 역시 이진 탐색 트리이다.
이진 탐색 트리는 데이터의 효율적인 검색, 삽입, 삭제에 사용되며, 평균적으로 O(log n)의 시간 복잡도를 가진다. 하지만, 최악의 경우(불균형 트리, 선형 구조)에는 O(n)의 시간 복잡도를 가질 수 있다.
AVL 트리
AVL 트리(Adelson-Velsky and Landis Tree)는 자가 균형 이진 탐색 트리의 한 종류로, 각 노드의 왼쪽과 오른쪽 서브트리의 높이 차이가 최대 1이 되도록 유지하는 트리이다. AVL 트리는 삽입과 삭제 연산 후에도 균형을 유지하기 위해 회전(Rotation) 연산을 사용한다. AVL 트리는 데이터의 효율적인 검색, 삽입, 삭제에 사용되며, 선형 구조를 방지하여 항상 O(log n)의 시간 복잡도를 가진다.
레드 블랙 트리
레드 블랙 트리(Red-Black Tree)는 자가 균형 이진 탐색 트리의 한 종류로, 각 노드가 레드(Red) 또는 블랙(Black) 색상을 가지며, 다음과 같은 속성을 만족한다.
- 루트 노드는 항상 블랙이다.
- 모든 잎 노드(NIL 노드)는 블랙이다.
- 레드 노드의 자식 노드는 모두 블랙이다(즉, 레드 노드는 연속해서 나타날 수 없다).
- 각 노드로부터 그 노드의 모든 자손 잎 노드에 이르는 경로에는 동일한 수의 블랙 노드가 포함되어야 한다.
레드 블랙 트리는 삽입과 삭제 연산 후에도 균형을 유지하기 위해 색상 변경과 회전(Rotation) 연산을 사용한다. 레드 블랙 트리는 데이터의 효율적인 검색, 삽입, 삭제에 사용되며, 항상 O(log n)의 시간 복잡도를 가진다.
힙
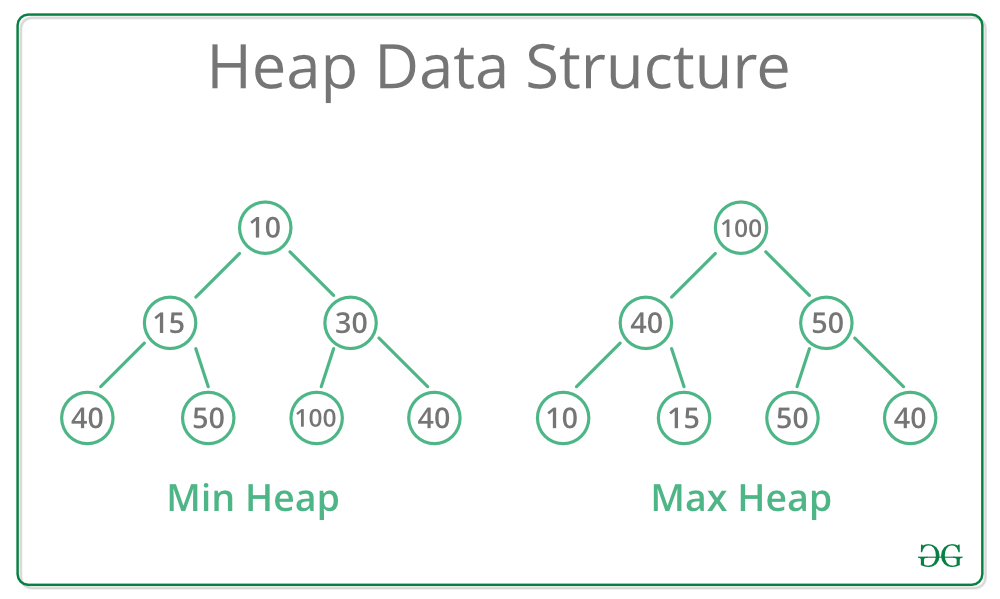
힙(Heap)은 완전 이진 트리의 일종으로, 부모 노드와 자식 노드 간의 특정한 순서 관계를 만족하는 자료 구조이다. 힙은 최대 힙(Max Heap)과 최소 힙(Min Heap)으로 나눌 수 있다. 각 서브 트리 역시 힙의 속성을 만족한다.
- 최대 힙(Max Heap): 부모 노드의 값이 자식 노드의 값보다 크거나 같은 힙이다. 따라서, 루트 노드에는 가장 큰 값이 위치한다.
- 최소 힙(Min Heap): 부모 노드의 값이 자식 노드의 값보다 작거나 같은 힙이다. 따라서, 루트 노드에는 가장 작은 값이 위치한다.
최대힙의 삽입과 삭제
최대 힙에서의 삽입과 삭제 연산은 다음과 같은 과정을 거친다.
-
삽입(Insertion): 1. 새로운 요소를 힙의 마지막 위치에 삽입한다. 2. 부모 노드와 비교하여 힙의 속성을 만족하지 않으면, 부모 노드와 교환한다(상향식 힙화, Bubble Up). 3. 이 과정을 루트 노드까지 반복한다.
-
삭제(Deletion): 1. 루트 노드를 제거하고, 힙의 마지막 요소를 루트 노드로 이동시킨다. 2. 자식 노드와 비교하여 힙의 속성을 만족하지 않으면, 자식 노드와 교환한다(하향식 힙화, Bubble Down). 3. 이 과정을 리프 노드까지 반복한다.
힙은 주로 우선순위 큐(Priority Queue) 구현에 사용되며, 힙 정렬(Heap Sort) 알고리즘에도 활용된다. 힙은 삽입과 삭제가 O(log n)의 시간 복잡도를 가지며, 탐색은 O(n)의 시간 복잡도를 가진다.
우선순위 큐
우선순위 큐(Priority Queue)는 각 요소가 우선순위를 가지며, 우선순위에 따라 요소가 처리되는 자료 구조이다. 우선순위 큐는 일반적인 큐와 달리, 가장 높은 우선순위를 가진 요소가 가장 먼저 제거된다. 우선순위 큐는 힙(Heap) 자료 구조를 사용하여 효율적으로 구현할 수 있다. 우선순위 큐는 작업 스케줄링, 이벤트 시뮬레이션, 다익스트라 알고리즘(Dijkstra's Algorithm) 등 다양한 분야에서 활용된다. 우선순위 큐는 삽입과 삭제가 O(log n)의 시간 복잡도를 가지며, 탐색은 O(n)의 시간 복잡도를 가진다.
맵
맵(Map)은 키-값 쌍으로 데이터를 저장하는 자료 구조로, 각 키는 고유하며 해당 키에 연결된 값을 빠르게 검색할 수 있다. 맵은 레드 블랙 트리(Red-Black Tree)와 같은 자가 균형 이진 탐색 트리로 구현되고 해시 맵(Hash Map)은 해시 테이블(Hash Table)로 구현될 수 있다. 맵은 삽입, 삭제, 검색이 평균적으로 O(log n)의 시간 복잡도를 가지며, 해시 맵의 경우 평균적으로 O(1)의 시간 복잡도를 가진다. 맵은 데이터베이스 인덱스, 캐시 구현, 설정 관리 등 다양한 응용 분야에서 활용된다.
셋
셋(Set)은 중복되지 않는 고유한 요소들의 집합을 저장하는 자료 구조로, 각 요소는 한 번만 포함될 수 있다. 셋은 레드 블랙 트리(Red-Black Tree)와 같은 자가 균형 이진 탐색 트리로 구현되고 해시 셋(Hash Set)은 해시 테이블(Hash Table)로 구현될 수 있다. 셋은 삽입, 삭제, 검색이 평균적으로 O(log n)의 시간 복잡도를 가지며, 해시 셋의 경우 평균적으로 O(1)의 시간 복잡도를 가진다. 셋은 데이터베이스 인덱스, 캐시 구현, 중복 제거 등 다양한 응용 분야에서 활용된다.
보통 맵과 셋은 내부적으로 같은 자료 구조로 구현되며, 맵은 키-값 쌍을 저장하고 셋은 키만 저장하는 차이가 있다.
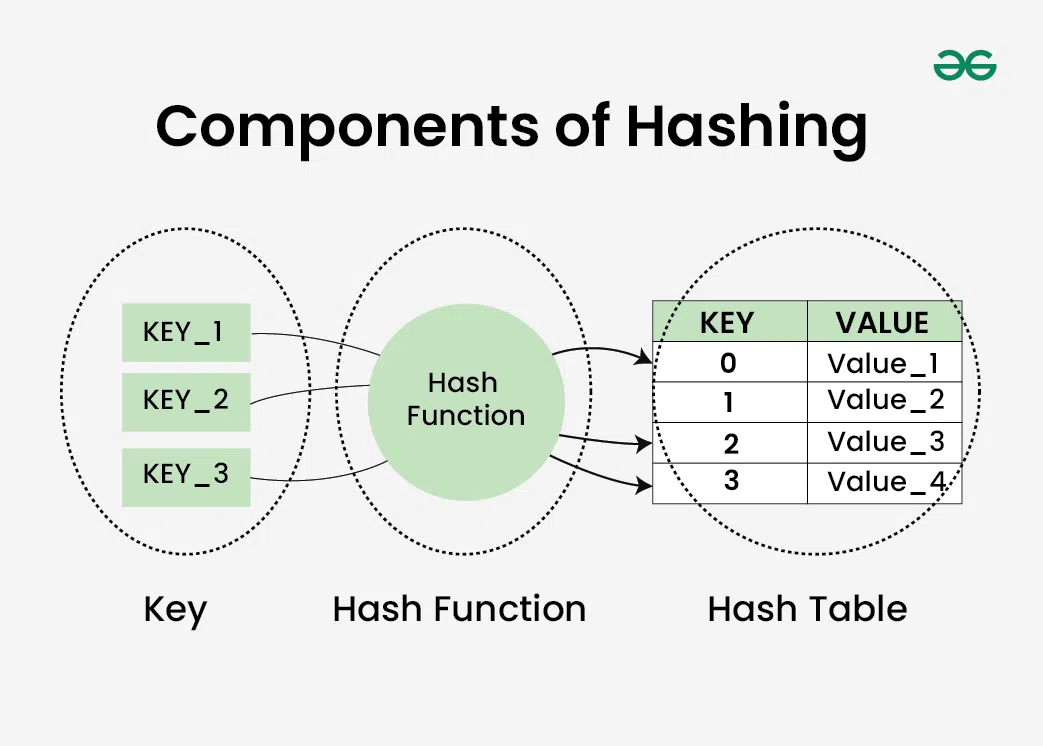
해시 테이블
해시 테이블(Hash Table)은 키-값 쌍으로 데이터를 저장하는 자료 구조로, 해시 함수를 사용하여 키를 해시 값으로 변환하고, 이 해시 값을 인덱스로 사용하여 값을 저장한다. 해시 테이블은 평균적으로 O(1)의 시간 복잡도를 가지며, 충돌 해결(Collision Resolution) 기법으로 체이닝(Chaining)과 오픈 어드레싱(Open Addressing)을 사용한다. 해시 테이블은 데이터베이스 인덱스, 캐시 구현, 설정 관리 등 다양한 응용 분야에서 활용된다.